on
Overfitting in Human Behavior
In machine learning, models will sometimes memorize parts of the training dataset instead of learning patterns that generalize beyond the examples it was presented. Statisticians refer to this phenomenon as overfitting. One thing I’ve noticed is that this fixation on specific examples and failure to generalize is not just a technical quirk of statistical modeling but something humans do as well.
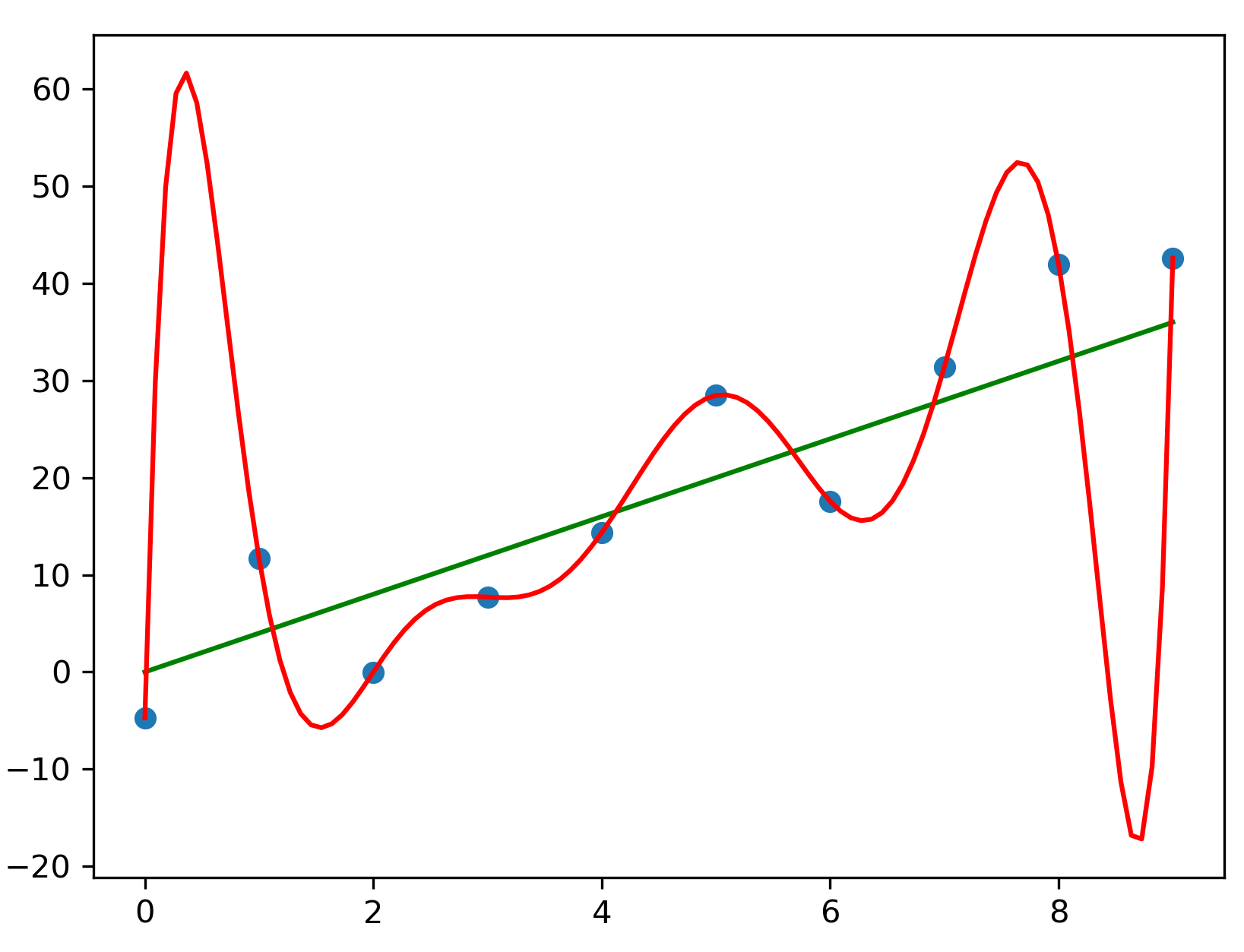
Perhaps the most egregious example of this is in education, where instructors optimize for standardized test scores, often focusing on teaching students how to respond to specific test questions or score high on a given rubric. Students often spend countless hours in expensive test preparation programs when the same results could have been achieved quicker and for free with a good textbook. Our cultural obsession with test scores has created this kafkaesque situation where students spend more time dealing with the bureaucracy of modern education than learning actual content.
The subject most infected by overfitting is by far mathematics. Mathematical education today places an outsized emphasis on memorization and rote learning. Students are often taught to mindlessly apply theorems and results without ever questioning their derivation, a practice that is fundamentally harmful in a subject with such an axiomatic nature.
Instructors will often give students the same problem with different numbers or worksheets that apply that same algorithm over and over again. Besides thoroughly extinguishing the mathematical elegance that emerges from deriving results from first principles, this kind of rote learning prevents students from learning the critical thinking skills required to deduce non-trivial results, often referred to as mathematical maturity.
In a world where large language models are saturating benchmarks faster than they can come out, the ability to think outside the box and generate novel ideas is more important than ever. We are doing students a disservice if we provide them with an education that puts them in the same class as generative AI.
I think this style of education is why students frequently struggle in physics courses. For many students, this is the first time they have encountered a subject that is fundamentally resistant to memorization, where blind application of formulae without conceptual understanding doesn’t work.
The first time I picked up a good physics textbook, I remember being struck by the level of mutual respect between the author and the reader. I was so used to the patronizing style of most texts from high school where entire chapters are devoted to covering a single unmotivated formula that I found the willingness of the author to derive results from scratch and then trust me to deduce their consequences refreshing. This kind of approach that respects the student was best put by physicist Richard Feynman:
I am going to give what I will call an elementary demonstration. But elementary does not mean easy to understand. Elementary means that very little is required to know ahead of time in order to understand it, except to have an infinite amount of intelligence. There may be a large number of steps to follow, but to each does not require already knowing the calculus or Fourier transforms.
⁂
Another fascinating case study into overfitting in humans is given in the amazingly titled article Fuck Nuance by Kieran Healey (yes, this is a real peer-reviewed paper). In the paper, Healey argues that contemporary literature in sociology is obsessed with criticizing concepts for their simplicity and failure to capture the complexities of a phenomenon:
the nuance-promoting theorist says, “But isn’t it more complicated than that?” or “Isn’t it really both/and?” or “Aren’t these phenomena mutually constitutive?” or “Aren’t you leaving out [something]?” or “How does the theory deal with agency, or structure, or culture, or temporality, or power, or [some other abstract noun]?” This sort of nuance is, I contend, fundamentally antitheoretical. It blocks the process of abstraction on which theory depends, and it inhibits the creative process that makes theorizing a useful activity.
Healey’s thesis reminds me a lot of a common mantra in statistics: All models are wrong, but some are useful. Because the world is endlessly multifaceted, any representation of it that we devise will necessarily be simplified. What makes a given representation scientific is the degree to which it allows us to make predictions. By ruling out unsuccessful theories and rigorously validating our successful ones, human knowledge converges closer to the truth.
In the social sciences, phenomena tend to be far more stochastic and multifactorial compared to the natural sciences. This has lead many in the “soft sciences” to try to emulate their “harder science” counterparts. One major difference between these fields is that compared to a discipline like physics, where something very close to a rigorous mathematical understanding of every facet of a phenomenon is possible, sociology can only provide qualitative descriptions of small parts of a bigger picture.
However, trying to have a framework simultaneously account for sexuality, race, gender, etc. as well as the original phenomenon often stultifies our theory with vagueness and undermines its ability to generalize beyond particular situations. This temptation to try to incorporate more and more parameters at the expense of its explanatory power seems like a textbook example of overfitting: the complexity of our hypothesis has exceeded what can be inferred from our dataset, leading to a loss in predictive power.
⁂
I have found this idea of overfitting very useful when thinking about situations where people place too much attention on specifics at the expense of the big picture, missing the forest for the trees. A friend pointed out to me that when ambitious people attempt to mimic the habits of billionaires by suddenly journaling, reading self-help, and putting butter in their coffee, that this can be interperted as a kind of overfitting. A lot of conspiratorial thinking, where people connect the dots to see a pattern that isn’t there, is also a case of overfitting.
With the release of increasingly capable LLMs, I’ve had many interesting conversations about the extent to which these systems are merely stochastic parrots or can “reason” in the same way humans do. I find that a lot of problems with developing machine learning systems interesting not only because of the technical challenges they present, but the way they correspond to challenges people face in their own lives. The inner workings of these artificial minds provide us with a window into our own.